Thinking about this some more, I believe the energy should be conserved so
that's what we're checking. I just had a look at some of the julia
implementations and they also differ quite a bit in their energies, except
for the original nbabel.jl which seems to go from E=-0.25 to E=0.5 in one
step, which seems non-physical to me. I guess the code is somewhat
numerically unstable, so if one would want to use this for simulations,
you'd have to adopt some sort of adaptive step-size, which somewhat raises
the question if this was the best code for comparison of the different
languages (not criticising you Pierre, I think this is really cool!).
On Wed, Jan 27, 2021 at 5:15 PM Jochen S <cycomanic@xxxxxxxxx> wrote:
Hi Pierre,
I just had a look at your code earlier and I get different energies
between the omp and non-omp version. I don't think that's expected?
make bench1k
t = 10.00, E = -0.2196519645, dE/E = +0.0000016603
make bench1k_omp
t = 10.00, E = -0.2362802267, dE/E = -0.0000019963
I had a look at the code, but didn't see anything obvious sticking out.
On Wed, Jan 27, 2021 at 3:52 PM PIERRE AUGIER <
pierre.augier@xxxxxxxxxxxxxxxxxxxxxx> wrote:
Finally, it wasn't difficult to adapt the C OpenMP code
https://github.com/jodavies/nbody/blob/openmp/src/nbody.c#L234 and I get
a Pythran version with a very good scaling!
Julia is a bit faster in sequential but the scaling is better for
Pythran, which makes it slightly faster for 12 threads (figures attached).
Anyway, such differences are not really meaningful.
But it's really good to have an efficient parallel implementation in
Python.
----- Mail original -----
De: "Jochen S" <cycomanic@xxxxxxxxx>production + OpenMP implementation?
À: "pythran" <pythran@xxxxxxxxxxxxx>
Envoyé: Mardi 26 Janvier 2021 22:26:26
Objet: [pythran] Re: Preliminary results benchmark NBabel CO2
Was about to say the same thing. Even leaving aside power consumption attends
rest, embedded energy is quite significant, so you always want to try
utilise your machine to the highest degree possible.
On Tue, Jan 26, 2021 at 8:51 PM PIERRE AUGIER <
pierre.augier@xxxxxxxxxxxxxxxxxxxxxx> wrote:
Even with a quite bad scaling for elapsed time, parallel computing
because weto decrease CO2 production as measured by these types of studies
powerconsider that the node is fully taken by the process. The power of the
whole node counts for this process even if only one core is used and we
could theoretically use the computer for other tasks. Moreover, the
powerat rest is not at all negligible compared to the power when one core is
running. For example, with the node I used for this experiment, the
with 12at rest is ~100 W, the power for sequential computing is ~130 W and
building.threads only ~220 W.
Moreover there is a cost in CO2/hour associated with the computer
production
Decreasing the elapsed time is therefore very important in term of CO2
production.
----- Mail original -----
De: "Neal Becker" <ndbecker2@xxxxxxxxx>
À: "pythran" <pythran@xxxxxxxxxxxxx>
Envoyé: Mardi 26 Janvier 2021 18:02:13
Objet: [pythran] Re: Preliminary results benchmark NBabel CO2
).+ OpenMP implementation?
I don't see how it's possible that parallel processing could reduceconsumption
total energy consumption. Now if you specify a deadline to produce
the results, it might be possible that a single computational element
power consumption might scale nonlinearly with clock speed, and in
that case running multiple cores at lower clock might produce the
result in the allotted time while consuming less energy, but I don't
think we had a time limit.
On Tue, Jan 26, 2021 at 11:53 AM Serge Guelton
<serge.guelton@xxxxxxxxxxxxxxxxxxx> wrote:
On Tue, Jan 26, 2021 at 02:07:43PM +0100, PIERRE AUGIER wrote:
Hi,
Here are some preliminary results of an experiment on energy
measurement at Grid'5000
(https://www.grid5000.fr/w/Energy_consumption_monitoring_tutorial
stopThe goal is
articleto have enough to be able to submit a serious comment to a recent
published in Nature Astronomy (Zwart, 2020) which recommends to
https://raw.githubusercontent.com/paugier/nbabel/master/py/fig/fig_ecolo_impact_transonic.pngusing and
https://github.com/paugier/nbabel):teaching Python because of the ecological impact of computing.
2 figures are attached (the code is here
different
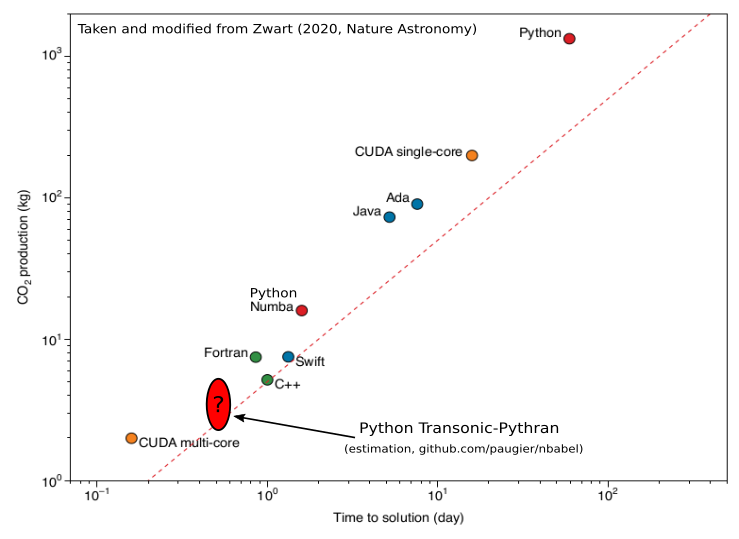
1. fig_bench_nbabel.png: CO2 production versus elapsed time for
implementations. This figure can be compared with
articletaken from Zwart (2020).
The implementations labeled "nbabel.org" have been found on
https://www.nbabel.org/ and have recently been used in the
deal).by Zwart
not well(2020). Note that these C++, Fortran and Julia implementations are
Fortran andoptimized. However, I think they are representative of many C++,
(slightly slowerJulia codes written by scientists.
There is one simple Pythran implementation which is really fast
than the fastest implementation in Julia but it is not a big
faster
Note that of course these results do not show that Python is
efficientthat C++!!
We just show here that it's easy to write in Python **very**
termsfunction ofimplementations of numerically intensive problems.
2. fig_bench_nbabel_parallel_julia.png shows similar results as a
decrease elapsedthe number of threads for a parallel Julia implementation.
The scaling is not very good but parallelization can of course
time and CO2 production.
If the scaling is not very good, then is parallelization good in
youof CO2
production? Imean, if using 1 core, you spend 10s and using 2 cores
secondspend
15s, then overall, what's the energy consumed in the first and
case? If
single-threaded optionthe nergy spent is linear to the number of core, then the
is better, energy-wise?
--
Those who don't understand recursion are doomed to repeat it
{kind=link}